《Getting Things Done》读书笔记
-
本文来自 inertial 原创投稿。
我第一次听说《Getting Things
Done》这本书的时候误以为它和世面上的那些成功学书籍没什么区别,后来在不少书中看到了这个名字,也看见了很多人的推荐,由此产生了很大的兴趣。上个月正好有不少空闲,就抽时间把这本书读完了。
本来打算读英文原版,但是原版的生...
5 年前
1,如果是从新创造一个Iplimage,则用IplImage* cvCreateImage( CvSize size, int depth, int channels ),它创建头并分配数据。
注:当不再使用这个新图像时,要调用void cvReleaseImage( IplImage** image )将它的头和图像数据释放!
2,如果有图像数据没有为图像头分配存储空间(即,没有为IplImage*指针分配动态存储空间),则先调用IplImage* cvCreateImageHeader( CvSize size, int depth, int channels )创建图像头,再调用void cvSetData( CvArr* arr, void* data, int step )指定图像数据,可以理解为将这个新图像的数据指针指向了一个已存在的图像数据上,不存在图像数据存储空间的分配操作。
注:当不再使用这个新图像时,要调用void cvReleaseImageHeader( IplImage** image )将它的图像头释放!
3,如果有图像数据也有图像头(用于IplImage为静态分配存储空间的情况),则先调用IplImage* cvInitImageHeader( CvSize size, int depth, int channels )更改图像头,再调用void cvSetData( CvArr* arr, void* data, int step )指定图像数据。
注:因为这个新图像使用的是其它图像的数据和已有的图像头,所以不能使用cvReleaseImage将它的头和图像数据释放,也不能使用cvReleaseData将它的图像数据释放!
4,如果从已有的一个图像创建,则用IplImage* cvCloneImage( const IplImage* image ),它制作图像的完整拷贝包括头、ROI和数据。
注:当不再使用这个新图像时,要调用void cvReleaseImage( IplImage** image )将它的头和图像数据释放!
OpenCV 编程入门
美国伊力诺理工学院计算机科学系Gady Adam
翻译:Mensch
内容
资料链接
C程序实例
图像数据结构
简介
OpenCV概述
什么是OpenCV
开源C/C++计算机视觉库.
面向实时应用进行优化.
跨操作系统/硬件/窗口管理器.
通用图像/视频载入、存储和获取.
由中、高层API构成.
为Intel®公司的 Integrated Performance Primitives (IPP) 提供了透明接口.
特性:
图像数据操作 (分配,释放, 复制, 设定, 转换).
图像与视频 I/O (基于文件/摄像头输入, 图像/视频文件输出).
矩阵与向量操作与线性代数计算(相乘, 求解, 特征值, 奇异值分解SVD).
各种动态数据结构(列表, 队列, 集, 树, 图).
基本图像处理(滤波, 边缘检测, 角点检测, 采样与插值, 色彩转换, 形态操作, 直方图, 图像金字塔).
结构分析(连接成分, 轮廓处理, 距离转换, 模板匹配, Hough转换, 多边形近似, 线性拟合, 椭圆拟合, Delaunay三角化).
摄像头标定 (寻找并跟踪标定模板, 标定, 基础矩阵估计, homography估计, 立体匹配).
动作分析(光流, 动作分割, 跟踪).
对象辨识 (特征方法, 隐马可夫链模型HMM).
基本GUI(显示图像/视频, 键盘鼠标操作, 滚动条).
图像标识 (直线, 圆锥, 多边形, 文本绘图)
OpenCV 模块:
cv - OpenCV 主要函数.
cvaux - 辅助 (实验性) OpenCV 函数.
cxcore - 数据结构与线性代数算法.
highgui - GUI函数.
资料链接
参考手册:
/docs/index.htm
网络资源:
官方网页: http://www.intel.com/technology/computing/opencv/
软件下载: http://sourceforge.net/projects/opencvlibrary/
书籍:
Open Source Computer Vision Library by Gary R. Bradski, Vadim Pisarevsky, and Jean-Yves Bouguet, Springer, 1st ed. (June, 2006).
视频处理例程 (位于 /samples/c/目录中):
色彩跟踪: camshiftdemo
点跟踪: lkdemo
动作分割: motempl
边缘检测: laplace
图像处理例程(位于/samples/c/目录中):
边缘检测: edge
分割: pyramid_segmentation
形态: morphology
直方图: demhist
距离转换: distrans
椭圆拟合 fitellipse
OpenCV 命名约定
函数命名:
cvActionTarget[Mod](...)
Action = 核心功能(例如 设定set, 创建create)
Target = 操作目标 (例如 轮廓contour, 多边形polygon)
[Mod] = 可选修饰词 (例如说明参数类型)
矩阵数据类型:
CV_(S|U|F)C
S = 带符号整数
U = 无符号整数
F = 浮点数
例: CV_8UC1 表示一个8位无符号单通道矩阵,
CV_32FC2 表示一个32位浮点双通道矩阵.
图像数据类型:
IPL_DEPTH_(S|U|F)
例: IPL_DEPTH_8U 表示一个8位无符号图像.
IPL_DEPTH_
头文件:
#include
#include
#include
#include // 不必要 - 该头文件已在 cv.h 文件中包含
编译命令
Linux系统:
g++ hello-world.cpp -o hello-world \
-I /usr/local/include/opencv -L /usr/local/lib \
-lm -lcv -lhighgui -lcvaux
Windows系统:
注意在项目属性中设好OpenCV头文件以及库文件的路径.
C程序实例
////////////////////////////////////////////////////////////////////////
//
// hello-world.cpp
//
// 一个简单的OpenCV程序
// 它从一个文件中读取图像,将色彩值颠倒,并显示结果.
//
////////////////////////////////////////////////////////////////////////
#include
#include
#include
#include
#include
int main(int argc, char *argv[])
{
IplImage* img = 0;
int height,width,step,channels;
uchar *data;
int i,j,k;
if(argc<2){>\n\7");
exit(0);
}
// 载入图像
img=cvLoadImage(argv[1]);
if(!img){
printf("Could not load image file: %s\n",argv[1]);
exit(0);
}
// 获取图像数据
height = img->height;
width = img->width;
step = img->widthStep;
channels = img->nChannels;
data = (uchar *)img->imageData;
printf("Processing a %dx%d image with %d channels\n",height,width,channels);
// 创建窗口
cvNamedWindow("mainWin", CV_WINDOW_AUTOSIZE);
cvMoveWindow("mainWin", 100, 100);
// 反色图像
for(i=0;i
GUI命令
窗口管理
创建并放置一个窗口:
cvNamedWindow("win1", CV_WINDOW_AUTOSIZE);
cvMoveWindow("win1", 100, 100); // 以屏幕左上角为起点的偏移量
读入图像:
IplImage* img=0;
img=cvLoadImage(fileName);
if(!img) printf("Could not load image file: %s\n",fileName);
显示图像:
cvShowImage("win1",img);
可显示彩色或灰度的字节/浮点图像。 彩色图像数据认定为BGR顺序.
关闭窗口:
cvDestroyWindow("win1");
改变窗口尺寸:
cvResizeWindow("win1",100,100); // 新的宽/高值(象素点)
输入设备
响应鼠标事件:
定义鼠标handler:
void mouseHandler(int event, int x, int y, int flags, void* param)
{
switch(event){
case CV_EVENT_LBUTTONDOWN:
if(flags & CV_EVENT_FLAG_CTRLKEY)
printf("Left button down with CTRL pressed\n");
break;
case CV_EVENT_LBUTTONUP:
printf("Left button up\n");
break;
}
}
// x,y: 针对左上角的像点坐标
// event: CV_EVENT_LBUTTONDOWN, CV_EVENT_RBUTTONDOWN, CV_EVENT_MBUTTONDOWN,
// CV_EVENT_LBUTTONUP, CV_EVENT_RBUTTONUP, CV_EVENT_MBUTTONUP,
// CV_EVENT_LBUTTONDBLCLK, CV_EVENT_RBUTTONDBLCLK, CV_EVENT_MBUTTONDBLCLK,
// CV_EVENT_MOUSEMOVE:
// flags: CV_EVENT_FLAG_CTRLKEY, CV_EVENT_FLAG_SHIFTKEY, CV_EVENT_FLAG_ALTKEY,
// CV_EVENT_FLAG_LBUTTON, CV_EVENT_FLAG_RBUTTON, CV_EVENT_FLAG_MBUTTON
注册handler:
mouseParam=5;
cvSetMouseCallback("win1",mouseHandler,&mouseParam);
响应键盘事件:
键盘没有事件handler.
直接获取键盘操作:
int key;
key=cvWaitKey(10); // 输入等待10ms
等待按键并获取键盘操作:
int key;
key=cvWaitKey(0); // 无限等待键盘输入
键盘输入循环:
while(1){
key=cvWaitKey(10);
if(key==27) break;
switch(key){
case 'h':
...
break;
case 'i':
...
break;
}
}
处理滚动条事件:
定义滚动条handler:
void trackbarHandler(int pos)
{
printf("Trackbar position: %d\n",pos);
}
注册handler:
int trackbarVal=25;
int maxVal=100;
cvCreateTrackbar("bar1", "win1", &trackbarVal ,maxVal , trackbarHandler);
获取滚动条当前位置:
int pos = cvGetTrackbarPos("bar1","win1");
设定滚动条位置:
cvSetTrackbarPos("bar1", "win1", 25);
OpenCV基础数据结构
图像数据结构
IPL 图像:
IplImage
|-- int nChannels; // 色彩通道数(1,2,3,4)
|-- int depth; // 象素色深:
| // IPL_DEPTH_8U, IPL_DEPTH_8S,
| // IPL_DEPTH_16U,IPL_DEPTH_16S,
| // IPL_DEPTH_32S,IPL_DEPTH_
| // IPL_DEPTH_
|-- int width; // 图像宽度(象素点数)
|-- int height; // 图像高度(象素点数)
|-- char* imageData; // 指针指向成一列排列的图像数据
| // 注意色彩顺序为BGR
|-- int dataOrder; // 0 - 彩色通道交叉存取 BGRBGRBGR,
| // 1 - 彩色通道分隔存取 BBBGGGRRR
| // 函数cvCreateImage只能创建交叉存取的图像
|-- int origin; // 0 - 起点为左上角,
| // 1 - 起点为右下角(Windows位图bitmap格式)
|-- int widthStep; // 每行图像数据所占字节大小
|-- int imageSize; // 图像数据所占字节大小 = 高度*每行图像数据字节大小
|-- struct _IplROI *roi;// 图像ROI. 若不为NULL则表示需要处理的图像
| // 区域.
|-- char *imageDataOrigin; // 指针指向图像数据原点
| // (用来校准图像存储单元的重新分配)
|
|-- int align; // 图像行校准: 4或8字节校准
| // OpenCV不采用它而使用widthStep
|-- char colorModel[4]; // 图像色彩模型 - 被OpenCV忽略
矩阵与向量
矩阵:
CvMat // 2维数组
|-- int type; // 元素类型(uchar,short,int,float,double)
|-- int step; // 一行所占字节长度
|-- int rows, cols; // 尺寸大小
|-- int height, width; // 备用尺寸参照
|-- union data;
|-- uchar* ptr; // 针对unsigned char矩阵的数据指针
|-- short* s; // 针对short矩阵的数据指针
|-- int* i; // 针对integer矩阵的数据指针
|-- float* fl; // 针对float矩阵的数据指针
|-- double* db; // 针对double矩阵的数据指针
CvMatND // N-维数组
|-- int type; // 元素类型(uchar,short,int,float,double)
|-- int dims; // 数组维数
|-- union data;
| |-- uchar* ptr; // 针对unsigned char矩阵的数据指针
| |-- short* s; // 针对short矩阵的数据指针
| |-- int* i; // 针对integer矩阵的数据指针
| |-- float* fl; // 针对float矩阵的数据指针
| |-- double* db; // 针对double矩阵的数据指针
|
|-- struct dim[]; // 每个维的信息
|-- size; // 该维内元素个数
|-- step; // 该维内元素之间偏移量
CvSparseMat // 稀疏N维数组
通用数组:
CvArr* // 仅作为函数参数,说明函数接受多种类型的数组,例如:
// IplImage*, CvMat* 或者 CvSeq*.
// 只需通过分析数组头部的前4字节便可确定数组类型
标量:
CvScalar
|-- double val[4]; //4D向量
初始化函数:
CvScalar s = cvScalar(double val0, double val1=0, double val2=0, double val3=0);
举例:
CvScalar s = cvScalar(20.0);
s.val[0]=10.0;
注意:初始化函数与数据结构同名,只是首字母小写. 它不是C++的构造函数.
其他数据结构
点:
CvPoint p = cvPoint(int x, int y);
CvPoint2D
CvPoint3D
例如:
p.x=5.0;
p.y=5.0;
长方形尺寸:
CvSize r = cvSize(int width, int height);
CvSize2D
带偏移量的长方形尺寸:
CvRect r = cvRect(int x, int y, int width, int height);
图像处理
分配与释放图像空间
分配图像空间:
IplImage* cvCreateImage(CvSize size, int depth, int channels);
size: cvSize(width,height);
depth: IPL_DEPTH_8U, IPL_DEPTH_8S, IPL_DEPTH_16U,
IPL_DEPTH_16S, IPL_DEPTH_32S, IPL_DEPTH_
channels: 1, 2, 3 or 4.
注意数据为交叉存取.彩色图像的数据编排为b
举例:
// 分配一个单通道字节图像
IplImage* img1=cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,1);
// 分配一个三通道浮点图像
IplImage* img2=cvCreateImage(cvSize(640,480),IPL_DEPTH_
释放图像空间:
IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,1);
cvReleaseImage(&img);
复制图像:
IplImage* img1=cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,1);
IplImage* img2;
img2=cvCloneImage(img1);
设定/获取兴趣区域:
void cvSetImageROI(IplImage* image, CvRect rect);
void cvResetImageROI(IplImage* image);
vRect cvGetImageROI(const IplImage* image);
大部分OpenCV函数都支持ROI.
设定/获取兴趣通道:
void cvSetImageCOI(IplImage* image, int coi); // 0=all
int cvGetImageCOI(const IplImage* image);
大部分OpenCV函数暂不支持COI.
读取存储图像
从文件中载入图像:
IplImage* img=0;
img=cvLoadImage(fileName);
if(!img) printf("Could not load image file: %s\n",fileName);
Supported image formats: BMP, DIB, JPEG, JPG, JPE, PNG, PBM, PGM, PPM,
SR, RAS, TIFF, TIF
载入图像默认转为3通道彩色图像. 如果不是,则需加flag:
img=cvLoadImage(fileName,flag);
flag: >0 载入图像转为三通道彩色图像
=0 载入图像转为单通道灰度图像
<0>
图像存储为图像文件:
if(!cvSaveImage(outFileName,img)) printf("Could not save: %s\n",outFileName);
输入文件格式由文件扩展名决定.
存取图像元素
假设需要读取在i行j列像点的第k通道. 其中, 行数i的范围为[0, height-1], 列数j的范围为[0, width-1], 通道k的范围为[0, nchannels-1].
间接存取: (比较通用, 但效率低, 可读取任一类型图像数据)
对单通道字节图像:
IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,1);
CvScalar s;
s=cvGet2D(img,i,j); // get the (i,j) pixel value
printf("intensity=%f\n",s.val[0]);
s.val[0]=111;
cvSet2D(img,i,j,s); // set the (i,j) pixel value
对多通道浮点或字节图像:
IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_
CvScalar s;
s=cvGet2D(img,i,j); // get the (i,j) pixel value
printf("B=%f, G=%f, R=%f\n",s.val[0],s.val[1],s.val[2]);
s.val[0]=111;
s.val[1]=111;
s.val[2]=111;
cvSet2D(img,i,j,s); // set the (i,j) pixel value
直接存取: (效率高, 但容易出错)
对单通道字节图像:
IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,1);
((uchar *)(img->imageData + i*img->widthStep))[j]=111;
对多通道字节图像:
IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,3);
((uchar *)(img->imageData + i*img->widthStep))[j*img->nChannels + 0]=111; // B
((uchar *)(img->imageData + i*img->widthStep))[j*img->nChannels + 1]=112; // G
((uchar *)(img->imageData + i*img->widthStep))[j*img->nChannels + 2]=113; // R
对多通道浮点图像:
IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_
((float *)(img->imageData + i*img->widthStep))[j*img->nChannels + 0]=111; // B
((float *)(img->imageData + i*img->widthStep))[j*img->nChannels + 1]=112; // G
((float *)(img->imageData + i*img->widthStep))[j*img->nChannels + 2]=113; // R
用指针直接存取 : (在某些情况下简单高效)
对单通道字节图像:
IplImage* img = cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,1);
int height = img->height;
int width = img->width;
int step = img->widthStep/sizeof(uchar);
uchar* data = (uchar *)img->imageData;
data[i*step+j] = 111;
对多通道字节图像:
IplImage* img = cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,3);
int height = img->height;
int width = img->width;
int step = img->widthStep/sizeof(uchar);
int channels = img->nChannels;
uchar* data = (uchar *)img->imageData;
data[i*step+j*channels+k] = 111;
对单通道浮点图像(假设用4字节调整):
IplImage* img = cvCreateImage(cvSize(640,480),IPL_DEPTH_
int height = img->height;
int width = img->width;
int step = img->widthStep/sizeof(float);
int channels = img->nChannels;
float * data = (float *)img->imageData;
data[i*step+j*channels+k] = 111;
使用 c++ wrapper 进行直接存取: (简单高效)
对单/多通道字节图像,多通道浮点图像定义一个 c++ wrapper:
template class Image
{
private:
IplImage* imgp;
public:
Image(IplImage* img=0) {imgp=img;}
~Image(){imgp=0;}
void operator=(IplImage* img) {imgp=img;}
inline T* operator[](const int rowIndx) {
return ((T *)(imgp->imageData + rowIndx*imgp->widthStep));}
};
typedef struct{
unsigned char b,g,r;
} RgbPixel;
typedef struct{
float b,g,r;
} RgbPixelFloat;
typedef Image RgbImage;
typedef Image RgbImageFloat;
typedef Image BwImage;
typedef Image BwImageFloat;
单通道字节图像:
IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,1);
BwImage imgA(img);
imgA[i][j] = 111;
多通道字节图像:
IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_8U,3);
RgbImage imgA(img);
imgA[i][j].b = 111;
imgA[i][j].g = 111;
imgA[i][j].r = 111;
多通道浮点图像:
IplImage* img=cvCreateImage(cvSize(640,480),IPL_DEPTH_
RgbImageFloat imgA(img);
imgA[i][j].b = 111;
imgA[i][j].g = 111;
imgA[i][j].r = 111;
图像转换
转为灰度或彩色字节图像:
cvConvertImage(src, dst, flags=0);
src = float/byte grayscale/color image
dst = byte grayscale/color image
flags = CV_CVTIMG_FLIP (flip vertically)
CV_CVTIMG_SWAP_RB (swap the R and B channels)
转换彩色图像为灰度图像:
使用OpenCV转换函数:
cvCvtColor(cimg,gimg,CV_BGR2GRAY); // cimg -> gimg
直接转换:
for(i=0;iheight;i++) for(j=0;jwidth;j++)
gimgA[i][j]= (uchar)(cimgA[i][j].b*0.114 +
cimgA[i][j].g*0.587 +
cimgA[i][j].r*0.299);
颜色空间转换:
cvCvtColor(src,dst,code); // src -> dst
code = CV_2
/ = RGB, BGR, GRAY, HSV, YCrCb, XYZ, Lab, Luv, HLS
e.g.: CV_BGR2GRAY, CV_BGR2HSV, CV_BGR2Lab
绘图命令
画长方体:
// 用宽度为1的红线在(100,100)与(200,200)之间画一长方体
cvRectangle(img, cvPoint(100,100), cvPoint(200,200), cvScalar(255,0,0), 1);
画圆:
// 在(100,100)处画一半径为20的圆,使用宽度为1的绿线
cvCircle(img, cvPoint(100,100), 20, cvScalar(0,255,0), 1);
画线段:
// 在(100,100)与(200,200)之间画绿色线段,宽度为1
cvLine(img, cvPoint(100,100), cvPoint(200,200), cvScalar(0,255,0), 1);
画一组线段:
CvPoint curve1[]={10,10, 10,100, 100,100, 100,10};
CvPoint curve2[]={30,30, 30,130, 130,130, 130,30, 150,10};
CvPoint* curveArr[2]={curve1, curve2};
int nCurvePts[2]={4,5};
int nCurves=2;
int isCurveClosed=1;
int lineWidth=1;
cvPolyLine(img,curveArr,nCurvePts,nCurves,isCurveClosed,cvScalar(0,255,255),lineWidth);
画内填充色的多边形:
cvFillPoly(img,curveArr,nCurvePts,nCurves,cvScalar(0,255,255));
添加文本:
CvFont font;
double hScale=1.0;
double vScale=1.0;
int lineWidth=1;
cvInitFont(&font,CV_FONT_HERSHEY_SIMPLEX|CV_FONT_ITALIC, hScale,vScale,0,lineWidth);
cvPutText (img,"My comment",cvPoint(200,400), &font, cvScalar(255,255,0));
Other possible fonts:
CV_FONT_HERSHEY_SIMPLEX, CV_FONT_HERSHEY_PLAIN,
CV_FONT_HERSHEY_DUPLEX, CV_FONT_HERSHEY_COMPLEX,
CV_FONT_HERSHEY_TRIPLEX, CV_FONT_HERSHEY_COMPLEX_SMALL,
CV_FONT_HERSHEY_SCRIPT_SIMPLEX, CV_FONT_HERSHEY_SCRIPT_COMPLEX,
矩阵操作
分配释放矩阵空间
综述:
OpenCV有针对矩阵操作的C语言函数. 许多其他方法提供了更加方便的C++接口,其效率与OpenCV一样.
OpenCV将向量作为1维矩阵处理.
矩阵按行存储,每行有4字节的校整.
分配矩阵空间:
CvMat* cvCreateMat(int rows, int cols, int type);
type: 矩阵元素类型. 格式为CV_(S|U|F)C.
例如: CV_8UC1 表示8位无符号单通道矩阵, CV_32SC2表示32位有符号双通道矩阵.
例程:
CvMat* M = cvCreateMat(4,4,CV_32FC1);
释放矩阵空间:
CvMat* M = cvCreateMat(4,4,CV_32FC1);
cvReleaseMat(&M);
复制矩阵:
CvMat* M1 = cvCreateMat(4,4,CV_32FC1);
CvMat* M2;
M2=cvCloneMat(M1);
初始化矩阵:
double a[] = { 1, 2, 3, 4,
5, 6, 7, 8,
9, 10, 11, 12 };
CvMat Ma=cvMat(3, 4, CV_64FC1, a);
另一种方法:
CvMat Ma;
cvInitMatHeader(&Ma, 3, 4, CV_64FC1, a);
初始化矩阵为单位阵:
CvMat* M = cvCreateMat(4,4,CV_32FC1);
cvSetIdentity(M); // 这里似乎有问题,不成功
存取矩阵元素
假设需要存取一个2维浮点矩阵的第(i,j)个元素.
间接存取矩阵元素:
cvmSet(M,i,j,2.0); // Set M(i,j)
t = cvmGet(M,i,j); // Get M(i,j)
直接存取,假设使用4-字节校正:
CvMat* M = cvCreateMat(4,4,CV_32FC1);
int n = M->cols;
float *data = M->data.fl;
data[i*n+j] = 3.0;
直接存取,校正字节任意:
CvMat* M = cvCreateMat(4,4,CV_32FC1);
int step = M->step/sizeof(float);
float *data = M->data.fl;
(data+i*step)[j] = 3.0;
直接存取一个初始化的矩阵元素:
double a[16];
CvMat Ma = cvMat(3, 4, CV_64FC1, a);
a[i*4+j] = 2.0; // Ma(i,j)=2.0;
矩阵/向量操作
矩阵-矩阵操作:
CvMat *Ma, *Mb, *Mc;
cvAdd(Ma, Mb, Mc); // Ma+Mb -> Mc
cvSub(Ma, Mb, Mc); // Ma-Mb -> Mc
cvMatMul(Ma, Mb, Mc); // Ma*Mb -> Mc
按元素的矩阵操作:
CvMat *Ma, *Mb, *Mc;
cvMul(Ma, Mb, Mc); // Ma.*Mb -> Mc
cvDiv(Ma, Mb, Mc); // Ma./Mb -> Mc
cvAddS(Ma, cvScalar(-10.0), Mc); // Ma.-10 -> Mc
向量乘积:
double va[] = {1, 2, 3};
double vb[] = {0, 0, 1};
double vc[3];
CvMat Va=cvMat(3, 1, CV_64FC1, va);
CvMat Vb=cvMat(3, 1, CV_64FC1, vb);
CvMat Vc=cvMat(3, 1, CV_64FC1, vc);
double res=cvDotProduct(&Va,&Vb); // 点乘: Va . Vb -> res
cvCrossProduct(&Va, &Vb, &Vc); // 向量积: Va x Vb -> Vc
end{verbatim}
注意 Va, Vb, Vc 在向量积中向量元素个数须相同.
单矩阵操作:
CvMat *Ma, *Mb;
cvTranspose(Ma, Mb); // transpose(Ma) -> Mb (不能对自身进行转置)
CvScalar t = cvTrace(Ma); // trace(Ma) -> t.val[0]
double d = cvDet(Ma); // det(Ma) -> d
cvInvert(Ma, Mb); // inv(Ma) -> Mb
非齐次线性系统求解:
CvMat* A = cvCreateMat(3,3,CV_32FC1);
CvMat* x = cvCreateMat(3,1,CV_32FC1);
CvMat* b = cvCreateMat(3,1,CV_32FC1);
cvSolve(&A, &b, &x); // solve (Ax=b) for x
特征值分析(针对对称矩阵):
CvMat* A = cvCreateMat(3,3,CV_32FC1);
CvMat* E = cvCreateMat(3,3,CV_32FC1);
CvMat* l = cvCreateMat(3,1,CV_32FC1);
cvEigenVV(&A, &E, &l); // l = A的特征值 (降序排列)
// E = 对应的特征向量 (每行)
奇异值分解SVD:
CvMat* A = cvCreateMat(3,3,CV_32FC1);
CvMat* U = cvCreateMat(3,3,CV_32FC1);
CvMat* D = cvCreateMat(3,3,CV_32FC1);
CvMat* V = cvCreateMat(3,3,CV_32FC1);
cvSVD(A, D, U, V, CV_SVD_U_T|CV_SVD_V_T); // A = U D V^T
标号使得 U 和 V 返回时被转置(若没有转置标号,则有问题不成功!!!).
视频序列操作
从视频序列中抓取一帧
OpenCV支持从摄像头或视频文件(AVI)中抓取图像.
从摄像头获取初始化:
CvCapture* capture = cvCaptureFromCAM(0); // capture from video device #0
从视频文件获取初始化:
CvCapture* capture = cvCaptureFromAVI("infile.avi");
抓取帧:
IplImage* img = 0;
if(!cvGrabFrame(capture)){ // 抓取一帧
printf("Could not grab a frame\n\7");
exit(0);
}
img=cvRetrieveFrame(capture); // 恢复获取的帧图像
要从多个摄像头同时获取图像, 首先从每个摄像头抓取一帧. 在抓取动作都结束后再恢复帧图像.
释放抓取源:
cvReleaseCapture(&capture);
注意由设备抓取的图像是由capture函数自动分配和释放的. 不要试图自己释放它.
获取/设定帧信息
获取设备特性:
cvQueryFrame(capture); // this call is necessary to get correct
// capture properties
int frameH = (int) cvGetCaptureProperty(capture, CV_CAP_PROP_FRAME_HEIGHT);
int frameW = (int) cvGetCaptureProperty(capture, CV_CAP_PROP_FRAME_WIDTH);
int fps = (int) cvGetCaptureProperty(capture, CV_CAP_PROP_FPS);
int numFrames = (int) cvGetCaptureProperty(capture, CV_CAP_PROP_FRAME_COUNT);
所有帧数似乎只与视频文件有关. 用摄像头时不对,奇怪!!!.
获取帧信息:
float posMsec = cvGetCaptureProperty(capture, CV_CAP_PROP_POS_MSEC);
int posFrames = (int) cvGetCaptureProperty(capture, CV_CAP_PROP_POS_FRAMES);
float posRatio = cvGetCaptureProperty(capture, CV_CAP_PROP_POS_AVI_RATIO);
获取所抓取帧在视频序列中的位置, 从首帧开始按[毫秒]算. 或者从首帧开始从0标号, 获取所抓取帧的标号. 或者取相对位置,首帧为0,末帧为1, 只对视频文件有效.
设定所抓取的第一帧标号:
// 从视频文件相对位置0.9处开始抓取
cvSetCaptureProperty(capture, CV_CAP_PROP_POS_AVI_RATIO, (double)0.9);
只对从视频文件抓取有效. 不过似乎也不成功!!!
存储视频文件
初始化视频存储器:
CvVideoWriter *writer = 0;
int isColor = 1;
int fps = 25; // or 30
int frameW = 640; // 744 for firewire cameras
int frameH = 480; // 480 for firewire cameras
writer=cvCreateVideoWriter("out.avi",CV_FOURCC('P','I','M','1'),
fps,cvSize(frameW,frameH),isColor);
其他有效编码:
CV_FOURCC('P','I','M','1') = MPEG-1 codec
CV_FOURCC('M','J','P','G') = motion-jpeg codec (does not work well)
CV_FOURCC('M', 'P', '4', '2') = MPEG-4.2 codec
CV_FOURCC('D', 'I', 'V', '3') = MPEG-4.3 codec
CV_FOURCC('D', 'I', 'V', 'X') = MPEG-4 codec
CV_FOURCC('U', '2', '6', '3') = H263 codec
CV_FOURCC('I', '2', '6', '3') = H263I codec
CV_FOURCC('F', 'L', 'V', '1') = FLV1 codec
若把视频编码设为-1则将打开一个编码选择窗口(windows系统下).
存储视频文件:
IplImage* img = 0;
int nFrames = 50;
for(i=0;i
若想在抓取中查看抓取图像, 可在循环中加入下列代码:
cvShowImage("mainWin", img);
key=cvWaitKey(20); // wait 20 ms
若没有20[毫秒]延迟,将无法正确显示视频序列.
释放视频存储器:
cvReleaseVideoWriter(&writer);
转自http://www.cnblogs.com/xiaotie/archive/2009/01/15/1376677.html
本文源自我之前花了2天时间做的一个简单的车牌识别系统。那个项目,时间太紧,样本也有限,达不到对方要求的95%识别率(主要对于车牌来说,D,0,O,I,1等等太相似了。然后,汉字的识别难度也不小),因此未被对方接受。在此放出,同时描述一下思路及算法。
全文分两部分,第一部分讲车牌识别及普通验证码这一类识别的普通方法,第二部分讲对类似QQ验证码,Gmail验证码这一类变态验证码的识别方法和思路。
一、车牌/验证码识别的普通方法
车牌、验证码识别的普通方法为:
(1) 将图片灰度化与二值化
(2) 去噪,然后切割成一个一个的字符
(3) 提取每一个字符的特征,生成特征矢量或特征矩阵
(4) 分类与学习。将特征矢量或特征矩阵与样本库进行比对,挑选出相似的那类样本,将这类样本的值作为输出结果。
下面借着代码,描述一下上述过程。因为更新SVN Server,我以前以bdb储存的代码访问不了,因此部分代码是用Reflector反编译过来的,望见谅。
(1) 图片的灰度化与二值化
这样做的目的是将图片的每一个象素变成0或者255,以便以计算。同时,也可以去除部分噪音。
图片的灰度化与二值化的前提是bmp图片,如果不是,则需要首先转换为bmp图片。
用代码说话,我的将图片灰度化的代码(算法是在网上搜到的):
通过将图片灰度化,每一个象素就变成了一个0-255的灰度值。
然后是将灰度值二值化为 0 或255。一般的处理方法是设定一个区间,比如,[a,b],将[a,b]之间的灰度全部变成255,其它的变成0。这里我采用的是网上广为流行的自适应二值化算法。
灰度化与二值化之前的图片:
![]()
灰度化与二值化之后的图片:
![]()
注:对于车牌识别来说,这个算法还不错。对于验证码识别,可能需要针对特定的网站设计特殊的二值化算法,以过滤杂色。
(2) 去噪,然后切割成一个一个的字符
上面这张车牌切割是比较简单的,从左到右扫描一下,碰见空大的,咔嚓一刀,就解决了。但有一些车牌,比如这张:
![]()
简单的扫描就解决不了。因此需要一个比较通用的去噪和切割算法。这里我采用的是比较朴素的方法:
将上面的图片看成是一个平面。将图片向水平方向投影,这样有字的地方的投影值就高,没字的地方投影得到的值就低。这样会得到一根曲线,像一个又一个山头。下面是我手画示意图:
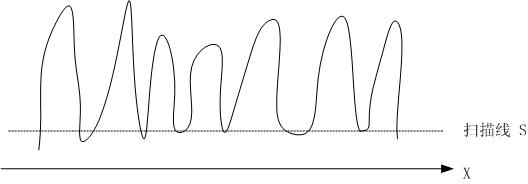
然后,用一根扫描线(上图中的S)从下向上扫描。这个扫描线会与图中曲线存在交点,这些交点会将山头分割成一个又一个区域。车牌图片一般是7个字符,因此,当扫描线将山头分割成七个区域时停止。然后根据这七个区域向水平线的投影的坐标就可以将图片中的七个字符分割出来。
但是,现实是复杂的。比如,“川”字,它的水平投影是三个山头。按上面 这种扫描方法会将它切开。因此,对于上面的切割,需要加上约束条件:每个山头有一个中心线,山头与山头的中心线的距离必需在某一个值之上,否则,则需要将 这两个山头进行合并。加上这个约束之后,便可以有效的切割了。
以上是水平投影。然后还需要做垂直投影与切割。这里的垂直投影与切割就一个山头,因此好处理一些。
切割结果如下:
水平投影及切割代码:
代码中的 Pair,代表扫描线与曲线的一对交点:
PairStatus代表Pair的状态。具体哪个状态是什么意义,我已经忘了。
以上这一段代码写的很辛苦,因为要处理很多特殊情况。那个PairStatus 也是为处理特殊情况引进的。
垂直投影与切割的代码简单一些,不贴了,见附后的dll的BitmapConverter.TrimHeight方法。
以上用到的是朴素的去噪与切割方法。有些图片,尤其是验证码图片,需要特别的去噪处理。具体操作方法就是,打开CxImage(http://www.codeproject.com/KB/graphics/cximage.aspx),或者Paint.Net,用上面的那些图片处理方法,看看能否有效去噪。记住自己的操作步骤,然后翻他们的源代码,将其中的算法提取出来。还有什么细化啊,滤波啊,这些处理可以提高图片的质量。具体可参考ITK的代码或图像处理书籍。
(3) 提取每一个字符的特征,生成特征矢量或特征矩阵
将切割出来的字符,分割成一个一个的小块,比如3×3,5×5,或3×5,或10×8,然后统计一下每小块的值为255的像素数量,这样得到一个矩阵M,或者将这个矩阵简化为矢量V。
通过以上3步,就可以将一个车牌中的字符数值化为矢量了。
(1)-(3)步具体的代码流程如下:

然后,通过spliter.ValueList就可以获得 Bitmap map0 的矢量表示。
(4) 分类
分类的原理很简单。用(Vij,Ci)表示一个样本。其中,Vij是样本图片经过上面过程数值化后的矢量。Ci是人肉眼识别这张图片,给出的结果。Vij表明,有多个样本,它们的数值化后的矢量不同,但是它们的结果都是Ci。假设待识别的图片矢量化后,得到的矢量是V’。
直观上,我们会有这样一个思路,就是这张待识别的图片,最像样本库中的某张图片,那么我们就将它当作那张图片,将它识别为样本库中那张图片事先指定的字符。
在我们眼睛里,判断一张图片和另一张图片是否相似很简单,但对于电脑来说,就很难判断了。我们前面已经将图片数值化为一个个维度一样的矢量,电脑是怎样判断一个矢量与另一个矢量相似的呢?
这里需要计算一个矢量与另一个矢量间的距离。这个距离越短,则认为这两个矢量越相似。
我用 SampleVector
T代表数据类型,可以为Int32,也可以为Double等更精确的类型。
测量距离的公共接口为:IMetric
常用的是MinkowskiMetric。
MinkowskiMetric是普遍使用的测度。但不一定是最有效的量。因为它对于矢量V中的每一个点都一视同仁。而在图像识别中,每一个点的重要性却并不一样,例如,Q和O的识别,特征在下半部分,下半部分的权重应该大于上半部分。对于这些易混淆的字符,需要设计特殊的测量方法。在车牌识别中,其它易混淆的有D和0,0和O,I和1。Minkowski Metric识别这些字符,效果很差。因此,当碰到这些字符时,需要进行特别的处理。由于当时时间紧,我就只用了Minkowski Metric。
我的代码中,只实现了哪个最近,就选哪个。更好的方案是用K近邻分类器或神经网络分类器。K近邻的原理是,找出和待识别的图片(矢量)距离最近的K个样本,然后让这K个样本使用某种规则计算(投票),这个新图片属于哪个类别(C);神经网络则将测量的过程和投票判决的过程参数化,使它可以随着样本的增加而改变,是这样的一种学习机。有兴趣的可以去看《模式分类》一书的第三章和第四章。
二、 变态字符的识别
有些字符变形很严重,有的字符连在一起互相交叉,有的字符被掩盖在一堆噪音海之中。对这类字符的识别需要用上特殊的手段。
下面介绍几种几个经典的处理方法,这些方法都是被证实对某些问题很有效的方法:
(1) 切线距离 (Tangent Distance):可用于处理字符的各种变形,OCR的核心技术之一。
(2) 霍夫变换(Hough Transform):对噪音极其不敏感,常用于从图片中提取各种形状。图像识别中最基本的方法之一。
(3) 形状上下文(Shape Context):将特征高维化,对形变不很敏感,对噪音也不很敏感。新世纪出现的新方法。
因为这几种方法我均未编码实现过,因此只简单介绍下原理及主要应用场景。
(1) 切线距离
前面介绍了MinkowskiMetric。这里我们看看下面这张图:一个正写的1与一个歪着的1.
![]()
用MinkowskiMetric计算的话,两者的MinkowskiMetric很大。
然而,在图像识别中,形状形变是常事。理论上,为了更好地识别,我们需要对每一种形变都采足够的样,这样一来,会发现样本数几乎无穷无尽,计算量越来越大。
怎么办呢?那就是通过计算切线距离,来代替直接距离。切线距离比较抽象,我们将问题简化为二维空间,以便以理解。
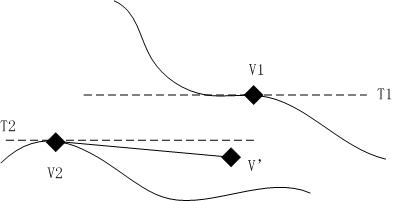
上图有两条曲线。分别是两个字符经过某一形变后所产生的轨迹。V1和V2是2个样本。V’是待识别图片。如果用样本之间的直接距离,比较哪个样本离V’最近,就将V’当作哪一类,这样的话,就要把V’分给V1了。理论上,如果我们无限取样的话,下面那一条曲线上的某个样本离V’最近,V’应该归类为V2。不过,无限取样不现实,于是就引出了切线距离:在样本V1,V2处做切线,然后计算V’离这两条切线的距离,哪个最近就算哪一类。这样一来,每一个样本,就可以代表它附近的一个样本区域,不需要海量的样本,也能有效的计算不同形状间的相似性。
深入了解切线距离,可参考这篇文章。Transformation invariance in pattern recognition – tangent distance and tangent propagation (http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.32.9482)这篇文章。
(2) 霍夫变换
霍夫变换出自1962年的一篇专利。它的原理非常简单:就是坐标变换的问题。
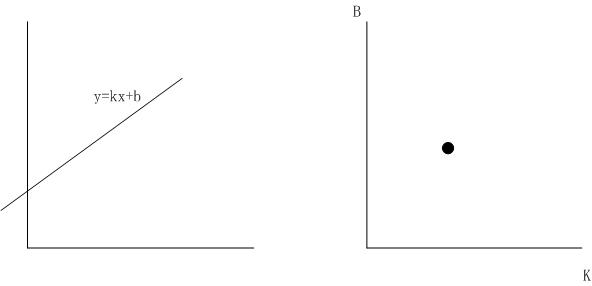
如,上图中左图中的直线,对应着有图中k-b坐标系中的一个点。通过坐标变换,可以将直线的识别转换为点的识别。点的识别就比直线识别简单的多。为了避免无限大无限小问题,常用的是如下变换公式:
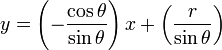
下面这张图是wikipedia上一张霍夫变换的示意图。左图中的两条直线变换后正对应着右图中的两个亮点。
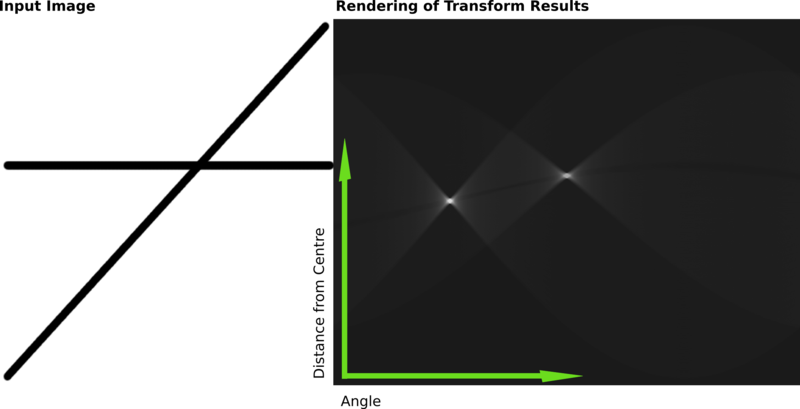
通过霍夫变换原理可以看出,它的抗干扰性极强极强:如果直线不是连续的,是断断续续的,变换之后仍然是一个点,只是这个点的强度要低一些。如果一个直线被一个矩形遮盖住了,同样不影响识别。因为这个特征,它的应用性非常广泛。
对于直线,圆这样容易被参数化的图像,霍夫变换是最擅长处理的。对于一般的曲线,可通过广义霍夫变换进行处理。感兴趣的可以google之,全是数学公式,看的人头疼。
(3) 形状上下文
图像中的像素点不是孤立的,每个像素点,处于一个形状背景之下,因此,在提取特征时,需要将像素点的背景也作为该像素点的特征提取出来,数值化。
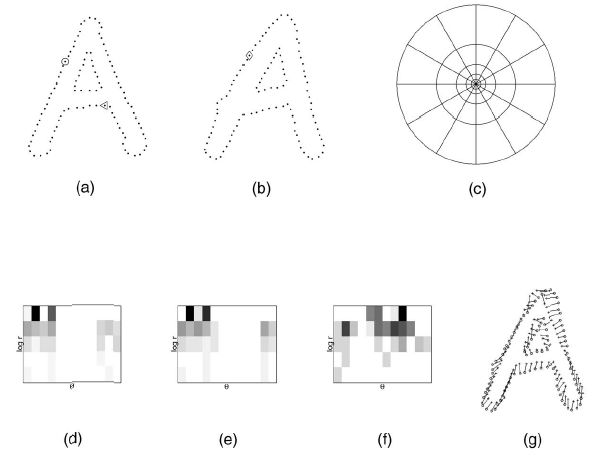
形状上下文(Shape Context,形状背景)就是这样一种方法:假定要提取像素点O的特征,采用上图(c)中的坐标系,以O点作为坐标系的圆心。这个坐标系将O点的上下左右切割成了12×5=60小块,然后统计这60小块之内的像素的特征,将其数值化为12×5的矩阵,上图中的(d),(e),(f)便分别是三个像素点的Shape Context数值化后的结果。如此一来,提取的每一个点的特征便包括了形状特征,加以计算,威力甚大。来看看Shape Context的威力:
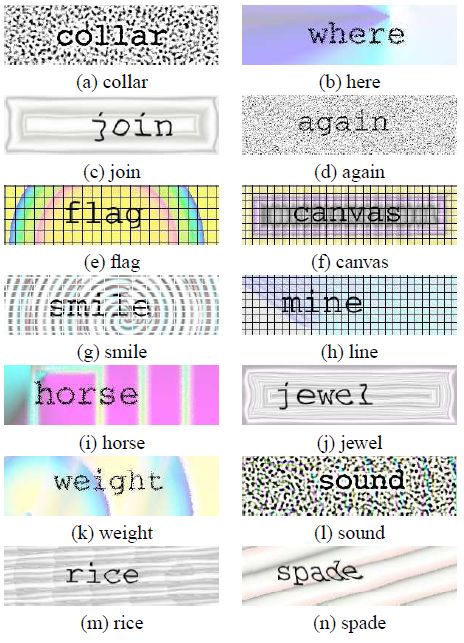
上图中的验证码,对Shape Context来说只是小Case。

看看这几张图。嘿嘿,硬是给识别出来了。
Shape Context是新出现的方法,其威力到底有多大目前还未见底。这篇文章是Shape context的必读文章:Shape Matching and Object Recognitiom using shape contexts(http://www.cs.berkeley.edu/~malik/papers/BMP-shape.pdf)。最后那两张验证码识别图出自Greg Mori,Jitendra Malik的《Recognizing Objects in Adversarial Clutter:Breaking a Visual CAPTCHA》一文。
===========================================================
附件:第一部分的代码(vcr.zip). 3个dll文件,反编译看的很清晰。源代码反而没dll好看,我就不放了。其中,Orc.Generics.dll是几个泛型 类,Orc.ImageProcess.Common.dll 对图像进行处理和分割,Orc.PatternRecognition.dll 是识别部分。
这三个dll可以直接用在车牌识别上。用于车牌识别,对易混淆的那几个字符识别率较差,需要补充几个分类器,现有分类器识别结果为D ,O,0,I,1等时,用新分类器识别。用于识别验证码需要改一改。
有个asp.net的调用例子可实现在线上传图片识别,因为其中包含多张车牌信息,不方便放出来。我贴部分代码出来:
Global.asax:
void Application_Start(object sender, EventArgs e)
{
log4net.Config.XmlConfigurator.Configure();
Orc.Spider.Vcr.DaoConfig.Init();
Classifier.Update(Server);
}
DaoConfig:
using System;
using Castle.ActiveRecord;
using Castle.ActiveRecord.Framework;
using Castle.ActiveRecord.Framework.Config;
namespace Orc.Spider.Vcr
{
public static class DaoConfig
{
private static Boolean Inited = false;
public static void Init()
{
if (!Inited)
{
Inited = true;
XmlConfigurationSource con = new XmlConfigurationSource(AppDomain.CurrentDomain.BaseDirectory + @"\ActiveRecord.config");
ActiveRecordStarter.Initialize
(con,
typeof(TrainPattern)
);
}
}
}
}
TrainPattern:// TrainPattern存在数据库里
[ActiveRecord("TrainPattern")]
public class TrainPattern : ActiveRecordBase<TrainPattern>
{
[PrimaryKey(PrimaryKeyType.Native, "Id")]
public Int32 Id { get; set; }
[Property("FileName")]
public String FileName { get; set; }
[Property("Category")]
public String Category { get; set; }
public static TrainPattern[] FindAll()
{
String hql = "from TrainPattern ORDER BY Category DESC";
SimpleQuery<TrainPattern> query = new SimpleQuery<TrainPattern>(hql);
return query.Execute();
}
}
Classifier://主要调用封装在这里
public class Classifier
{
protected static Orc.PatternRecognition.KnnClassifier<Int32> DefaultChineseCharClassifier;
protected static Orc.PatternRecognition.KnnClassifier<Int32> DefaultEnglishAndNumberCharClassifier;
protected static Orc.PatternRecognition.KnnClassifier<Int32> DefaultNumberCharClassifier;
public static Int32 DefaultWidthSplitCount = 3;
public static Int32 DefaultHeightSplitCount = 3;
public static Int32 DefaultCharsCount = 7; // 一张图片中包含的字符个数
public static Int32 DefaultHeightTrimThresholdValue = 4;
public static ILog Log = LogManager.GetLogger("Vcr");
public static void Update(HttpServerUtility server)
{
TrainPattern[] TPList = TrainPattern.FindAll();
if (TPList == null) return;
DefaultChineseCharClassifier = new KnnClassifier<Int32>(DefaultWidthSplitCount * DefaultHeightSplitCount);
DefaultEnglishAndNumberCharClassifier = new KnnClassifier<Int32>(DefaultWidthSplitCount * DefaultHeightSplitCount);
DefaultNumberCharClassifier = new KnnClassifier<Int32>(DefaultWidthSplitCount * DefaultHeightSplitCount);
foreach (TrainPattern tp in TPList)
{
String path = server.MapPath(".") + "/VcrImage/" + tp.FileName;
using (Bitmap bitmap = new Bitmap(path))
{
TrainPattern<Int32> tpv = CreateTainPatternVector(bitmap, tp.Category.Substring(0, 1));
Char c = tpv.Category[0];
if (c >= '0' && c <= '9')
{
DefaultEnglishAndNumberCharClassifier.AddTrainPattern(tpv);
DefaultNumberCharClassifier.AddTrainPattern(tpv);
}
else if (c >= 'a' && c <= 'z')
DefaultEnglishAndNumberCharClassifier.AddTrainPattern(tpv);
else if (c >= 'A' && c <= 'Z')
DefaultEnglishAndNumberCharClassifier.AddTrainPattern(tpv);
else
DefaultChineseCharClassifier.AddTrainPattern(tpv);
}
}
}
protected static TrainPattern<Int32> CreateTainPatternVector(Bitmap bitmap, String categoryChars)
{
TrainPattern<int> tpv = new TrainPattern<int>( CreateSampleVector(bitmap), categoryChars);
tpv.XNormalSample = CreateXNormalSampleVector(bitmap);
tpv.YNormalSample = CreateYNormalSampleVector(bitmap);
return tpv;
}
protected static SampleVector<Int32> CreateSampleVector(Bitmap bitmap)
{
ImageSpliter spliter = new ImageSpliter(bitmap);
spliter.WidthSplitCount = DefaultWidthSplitCount;
spliter.HeightSplitCount = DefaultHeightSplitCount;
spliter.Init();
return new SampleVector<Int32>(spliter.ValueList);
}
protected static SampleVector<Int32> CreateYNormalSampleVector(Bitmap bitmap)
{
ImageSpliter spliter = new ImageSpliter(bitmap);
spliter.WidthSplitCount = 1;
spliter.HeightSplitCount = DefaultHeightSplitCount;
spliter.Init();
return new SampleVector<Int32>(spliter.ValueList);
}
protected static SampleVector<Int32> CreateXNormalSampleVector(Bitmap bitmap)
{
ImageSpliter spliter = new ImageSpliter(bitmap);
spliter.WidthSplitCount = DefaultWidthSplitCount;
spliter.HeightSplitCount = 1;
spliter.Init();
return new SampleVector<Int32>(spliter.ValueList);
}
public static String Classify(String imageFileName)
{
Log.Debug("识别文件:" + imageFileName);
String result = String.Empty;
if (DefaultChineseCharClassifier == null || DefaultEnglishAndNumberCharClassifier == null) throw new Exception("识别器未初始化.");
using (Bitmap bitmap = new Bitmap(imageFileName))
{
BitmapConverter.ToGrayBmp(bitmap);
BitmapConverter.Binarizate(bitmap);
IList<Bitmap> mapList = BitmapConverter.Split(bitmap, DefaultCharsCount);
if (mapList.Count == DefaultCharsCount)
{
Bitmap map0 = BitmapConverter.TrimHeight(mapList[0], DefaultHeightTrimThresholdValue);
TrainPattern<Int32> tp0 = CreateTainPatternVector(map0, " ");
String sv0Result = DefaultChineseCharClassifier.Classify(tp0);
Console.WriteLine("识别样本: " + tp0.Sample.ToString());
result += sv0Result;
for (int i = 1; i < mapList.Count; i++)
{
Bitmap mapi = BitmapConverter.TrimHeight(mapList[i], DefaultHeightTrimThresholdValue);
TrainPattern<Int32> tpi = CreateTainPatternVector(mapi, " ");
Console.WriteLine("识别样本: " + tpi.Sample.ToString());
if (i < mapList.Count - 3)
result += DefaultEnglishAndNumberCharClassifier.Classify(tpi);
else
result += DefaultNumberCharClassifier.Classify(tpi);
}
}
return result;
}
}
/*
public static IList
{
if (DefaultChineseCharClassifier == null) throw new Exception("识别器未初始化.");
using (Bitmap bitmap = new Bitmap(imageFileName))
{
ImageSpliter spliter = new ImageSpliter(bitmap);
spliter.WidthSplitCount = DefaultWidthSplitCount;
spliter.HeightSplitCount = DefaultHeightSplitCount;
spliter.Init();
SampleVector
return DefaultChineseCharClassifier.ComputeDistance(sv);
}
}
}


